
TLDR
A frozen row is a row whose inserting transaction is so safely in the past that Postgres can treat it as visible to all future transactions. This helps vacuum avoid transaction ID wraparound issues.
What does a frozen row mean in Postgres?
If you’ve ever looked at the docs for vacuuming in Postgres, you may have seen the term “freezing rows”. If you are anything like me, that probably did not make sense at first. So I thought I would create a quick blog post explaining it and hopefully not get it too wrong.

The basics
Because Postgres uses MVCC, every time a row is modified it creates a new row version with the new data. The old row version has metadata fields that are used to keep track of which data is fresh (the data that should be seen by new queries) and which data is stale (the data that may still be seen by old queries). It uses XMIN and XMAX for this: XMIN is the transaction id that inserted the row, and XMAX is usually the transaction id that deleted, updated, or locked that row. So, for example, if we update an existing row, we will see 2 rows: one with an xmin of 10 and an xmax of 11, and the other with an xmin of 11 and no xmax because it is the fresh data at the moment and there is no newer data than that.
DROP TABLECREATE TABLE
== Insert one visible row version ==INSERT 0 1 ctid | xmin | xmax | id | name | former_team-------+------+------+----+------+------------------ (0,1) | 1108 | 0 | 1 | Luke | Coinbase support(1 row)
== Update the row: PostgreSQL creates a new tuple version ==UPDATE 1
== Normal SELECT: only the currently visible tuple version appears == ctid | xmin | xmax | id | name | former_team-------+------+------+----+-------+--------------------------- (0,2) | 1109 | 0 | 1 | Lucas | Coinbase button polishing(1 row)
== Optional deep view: physical tuple versions with pageinspect ==This requires permission to CREATE EXTENSION pageinspect.NOTICE: extension "pageinspect" already exists, skippingCREATE EXTENSION page_no | line_pointer | tuple_xmin | tuple_xmax | tuple_ctid | t_infomask | t_infomask2---------+--------------+------------+------------+------------+------------+------------- 0 | 1 | 1108 | 1109 | (0,2) | 1282 | 16387 0 | 2 | 1109 | 0 | (0,2) | 10498 | 32771(2 rows)After UPDATE, the old tuple has xmax set to the updating transaction id. The new tuple has xmin set to that same transaction id, and xmax is unset until it is modified again.
Why freeze a row
So with all this in mind, why do we need to freeze a row? Transaction IDs are a fixed size and can wrap around, so Postgres needs a way to mark very old rows as definitely in the past. Vacuum also figures out which rows are stale and can be deleted safely, and which rows are fresh and need to be kept, but freezing is mainly about avoiding transaction ID wraparound. If we used the naive approach and scanned the whole database looking at all the rows, that would be inefficient in compute, I/O, and memory. So Postgres uses optimizations like the visibility map, which marks pages as all-visible or all-frozen, so vacuum can skip pages that do not need the same kind of work.
There is also a special xid called FrozenTransactionId, which is 2.
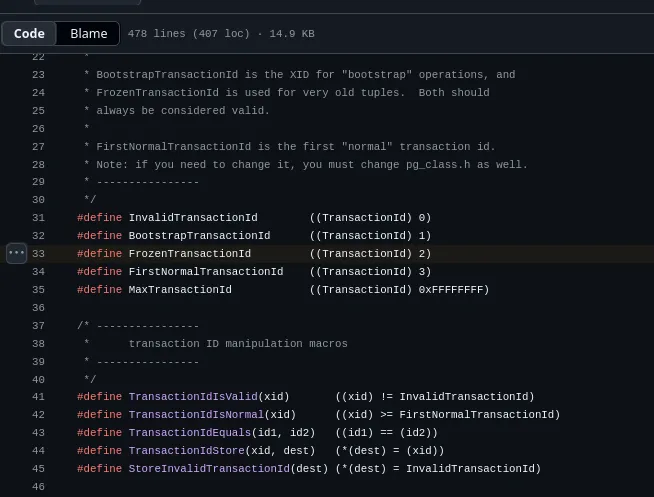
In modern Postgres (after 9.6), freezing normally does not replace the xmin value with FrozenTransactionId. It marks the tuple as frozen using tuple metadata, so Postgres can treat that old xmin as safely in the past. This helps avoid the wraparound issue because if Postgres wraps around and starts using low transaction IDs again, old rows will not look like they came from the future. For example, an old row might have xmin 2167. After around 2 billion more transactions (congrats on storing so much data; you must be doing something incredibly well or something incredibly wrong), that old xid is getting close to the danger zone and the row needs to be frozen so there is no chance of it being seen as new data when it is actually old data.
Why is 2 billion the danger zone?
The reason 2 billion is used is that the xid field for xmin and xmax is 32 bits long, which gives about 4 billion possible transaction IDs (or, to be precise, 4,294,967,296 IDs). Postgres compares these IDs using wraparound-aware maths, so from any current xid there are about 2 billion transaction IDs that count as being in the past and about 2 billion that count as being in the future.

For example, imagine a very old row has xmin = 10. If we just check whether 10 < 2,147,483,659, then yes, that is true, but Postgres cannot only check that because transaction IDs wrap around. After xid 4,294,967,295, the next xid is 3 (the first 3 xids are special; e.g. xid 2 is for frozen transactions in Postgres versions older than 9.6), and eventually 10 appears again.
So Postgres has to do a different check and ask: where is xmin = 10 on the xid circle compared with the current xid?
The whole circle is:
2^32 = 4,294,967,296 xid valuesHalf the circle is:
2^31 = 2,147,483,648 xid valuesThat means the danger line for xmin = 10 is:
10 + 2,147,483,648 = 2,147,483,658If the current transaction id is 2,147,483,657, then xmin = 10 is still 2,147,483,647 transactions behind the current xid. That is just inside the past half of the circle, so Postgres can still treat it as old.
2,147,483,657 - 10 = 2,147,483,647But if the current transaction id moves to 2,147,483,659, then xmin = 10 is now 2,147,483,649 transactions behind if you count along the normal number line. That is one step over the halfway point.
2,147,483,659 - 10 = 2,147,483,649and 2,147,483,649 > 2^31On the xid circle, 10 is closer if you go forward from 2,147,483,659 through wraparound than if you go backward from 2,147,483,659 to 10. So 10 stops looking like a very old xid and starts looking like an xid coming up after wraparound.
Another example where normal integer comparison is obviously wrong is after the counter wraps:
old xid = 4,294,967,290current xid = 10
Normal comparison:4,294,967,290 > 10The old xid is numerically bigger than 10, but it is only 16 transactions behind the current xid because the counter wrapped. This is why Postgres cannot just do normal comparisons and needs to have this wraparound-aware logic so it does not break if you ever do need to wrap around.
Postgres needs to freeze old tuples before they ever get close to that point so a very old row does not suddenly become invisible or confusing when the transaction id counter keeps moving around the circle. If Postgres could not mark rows as frozen, old rows could start being treated as newer rows, which would result in data loss and more layoffs happening, and we do not want that.
In Conclusion
I probably should not have used the actual numbers to show the wraparound logic, as it makes things more confusing than they need to be. Frozen rows are, I think, a smart way to handle the limited 32-bit space for a transaction id while still supporting more than 4 billion transactions over a database’s lifetime (and again, congrats on getting so much data). I hope you have enjoyed this article and it was not too bad.
